Introduction to GreenWave AI
GreenWave AI is a smart traffic light control system utilizing Artificial Intelligence (AI) and Reinforcement Learning, completely integrated with the FIWARE platform and SUMO traffic simulation.
Overview
Unlike traditional traffic light systems that use fixed-time counters, GreenWave AI analyzes traffic flow in real-time to make the most optimal control decisions.
The system operates based on the principle: "Green lights are only for directions that truly need them".
Key Features
- Independent Control: Each traffic light pillar is analyzed and controlled independently by AI, not rigidly dependent on other lights.
- Real-time: Decisions are made every 2 seconds based on current data from sensors.
- Conflict-Free: The algorithm ensures safety, ensuring that signal conflicts never occur.
- Multi-Objective: Simultaneously optimizes multiple metrics: queue length, waiting time, and vehicle density.
System Architecture
GreenWave AI operates according to the following closed-loop pipeline:
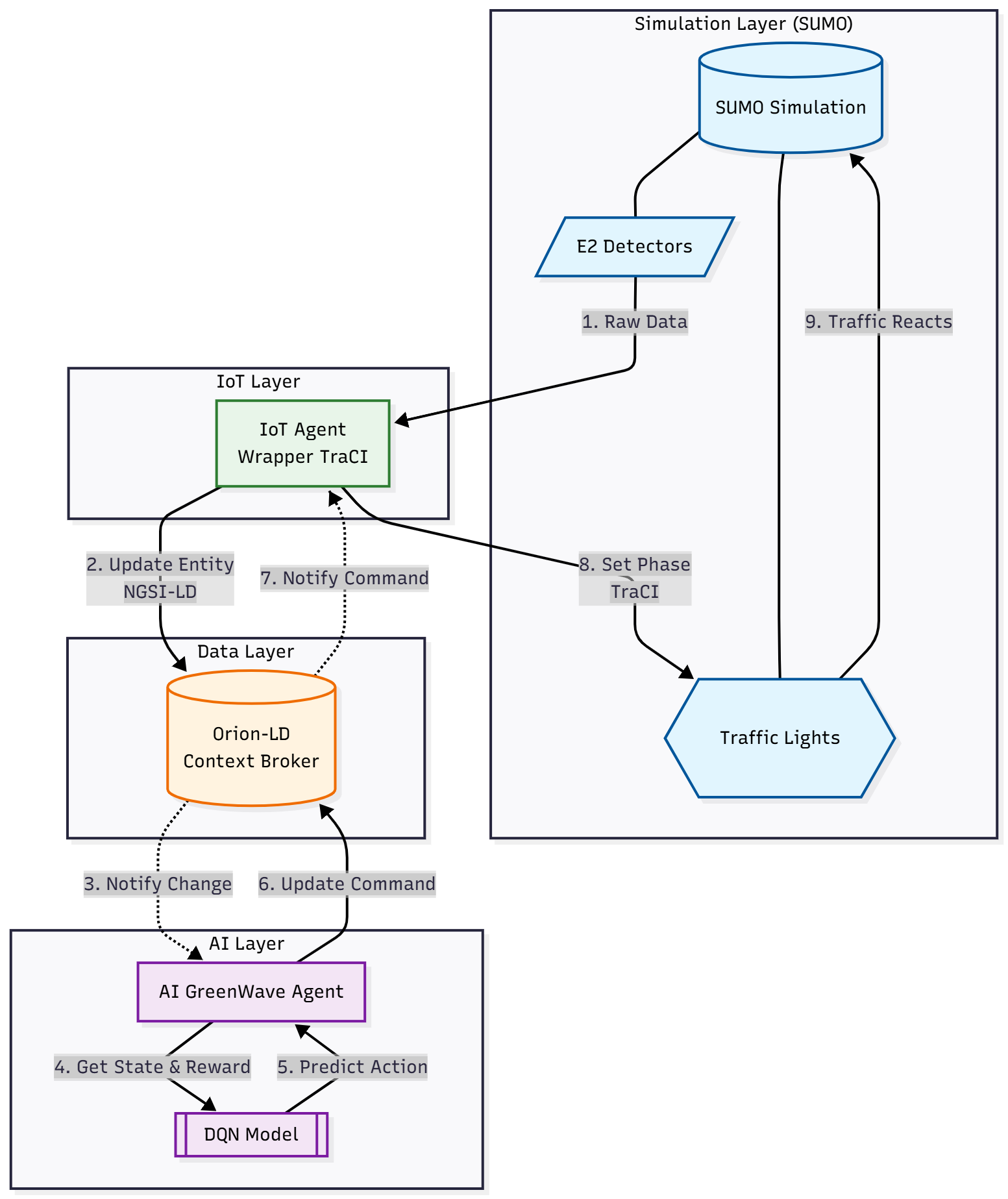
- Data Collection: Sensors (Induction loops) in SUMO collect information about speed and vehicle count.
- Context Broker: Data is normalized into TrafficFlowObserved and sent to Orion-LD.
- AI Processing: The AI Agent receives notifications from Orion, analyzes the state, and makes a phase decision.
- Execution: Control commands are sent back via the IoT Agent to change the light status in the simulation.
Artificial Intelligence & Algorithms
GreenWave employs Reinforcement Learning (RL) to solve the Traffic Signal Control (TSC) problem. Unlike traditional timer-based systems or static sensors, this AI learns optimal strategies by interacting with the simulation.
Algorithm: Deep Q-Network (DQN)
We use a Double DQN (Deep Q-Network) approach to stabilize learning.
- Model Architecture: A multi-layer perceptron (Neural Network) built with TensorFlow/Keras.
- Input Layer: 4 Neurons (State State).
- Hidden Layer 1: 128 Neurons (ReLU activation, Dropout 0.2).
- Hidden Layer 2: 128 Neurons (ReLU activation, Dropout 0.2).
- Hidden Layer 3: 64 Neurons (ReLU activation).
- Output Layer: 2 Neurons (Linear activation) representing Q-values for each action.
- Optimizer: Adam (Learning Rate = 0.0005).
- Loss Function: Mean Squared Error (MSE).
The "Dataset" (Experience Replay)
In Reinforcement Learning, there is no static "dataset" (like CSVs or Images). The AI creates its own dataset to learn from by interacting with the environment:
- Source: Analysis of real-time simulation frames (SUMO).
- Experience Replay Buffer: Stores the last 10,000 interaction steps.
- Format:
(State, Action, Reward, Next_State).
- Format:
- Training: The model samples a random "batch" (size 64) from this buffer to train itself, ensuring it learns from both recent and past experiences (preventing forgetting).
State Space (Input)
The AI "sees" the intersection through a vector of 4 values:
- Queue Length (Detector 1): Number of cars waiting at the North/South arm.
- Queue Length (Detector 2): Number of cars waiting at the East/West arm.
- Current Phase: Which light is currently green? (Index).
- PM2.5 Emission: Total air pollution calculated from vehicle emissions in the area.
Action Space (Output)
The AI can make 2 Decisions at every step:
- Action 0 (HOLD): Keep the current light Green.
- Action 1 (SWITCH): Switch the light to Red (and the other to Green).
- Constraint: The system enforces a Minimum Green Time (e.g., 10 seconds) to prevent chaotic, rapid switching.
Goal & Reward Function
The AI's goal is to maximize the "Reward". Our reward function is designed to balance traffic flow and environmental impact:
Reward = (0.6 × -TotalQueue) + (0.4 × -TotalPM2.5)
- Logic: The reward is always negative (a penalty). The AI tries to get this number as close to zero as possible.
- Traffic Priority (60%): Minimizing queues is the main goal.
- Eco Priority (40%): If two actions reduce queues equally, the AI picks the one that generates less pollution (e.g., keeping heavy trucks moving).
Performance & Effectiveness
- Adaptive: Unlike fixed-time lights, this system adapts to rush hour vs. midnight traffic automatically.
- Multi-objective: It solves not just for speed, but for Sustainability (Green Wave).
- Evaluation: During training, we observed a reduction in average waiting times compared to static timing, specifically in high-load scenarios (saturated intersections).